Event Detection and Analysis in Longitudinal Data
 Forecasting
Forecasting
| September 1, 2015 – August 31, 2018
- Forecasting
New Machine Learning Approaches for Modeling Time-to-Event Data
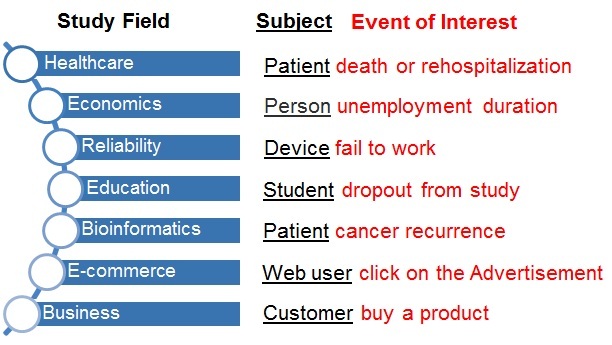
Various advancements in data acquisition and storage technologies have allowed different disciplines to attain the ability to not only accumulate a wide variety of data but also to monitor observations over longer time periods. In many practical domains, the primary objective of monitoring these observations is to better understand and estimate the time point at which a particular event of interest will occur in the future. In such longitudinal studies, one of the impending challenges is to estimate the occurrence of an event of interest since the data is typically censored, i.e., it is often incomplete since some of the instances will either become unobservable or no event occurs during the monitored duration. Due to this censored nature of the data, standard statistical and machine learning based predictive algorithms cannot readily be applied for analysis and forecasting.
Such data appears in a wide range of disciplines ranging from engineering to medicine to social science to education. In addition to the presence of censoring, such longitudinal event data poses unique challenges to the field of predictive analytics and thus necessitates the development of newer and more sophisticated solutions. In practice, these censored data challenges are compounded by several other closely related complexities such as the presence of correlations within the data, high dimensionality of the data, temporal dependencies across multiple time points, lack of available information from a single source, and difficulty in acquiring sufficient event data in a reasonable amount of time.
This project focuses on developing a suite of computational algorithms that can address these challenges and effectively capture the underlying predictive patterns in longitudinal data by directly estimating the probability of event occurrence. As an important analysis tool for such longitudinal data, new survival analysis methods are developed for several real-world domains where the observations start from a given time point and continue until the occurrence of a certain event or the observed objects become missing (not observed) from the study. In spite of the wide presence of such data in various disciplines and the potential impact a coherent toolkit can bring in such important research domains, there is no existing platform for longitudinal data analysis, primarily because the development of new computational methods for solving these longitudinal data problems is usually spread across various disciplines such as statistics, biomedicine, industrial engineering, machine learning, data analytics and optimization communities, to name a few.
The progress of the project and the research findings are disseminated via the project website.
People

Sponsors

National Science Foundation