Robust Intelligence
 Natural Language Processing
Natural Language Processing
| June 1, 2018 – May 31, 2020
- Natural Language Processing
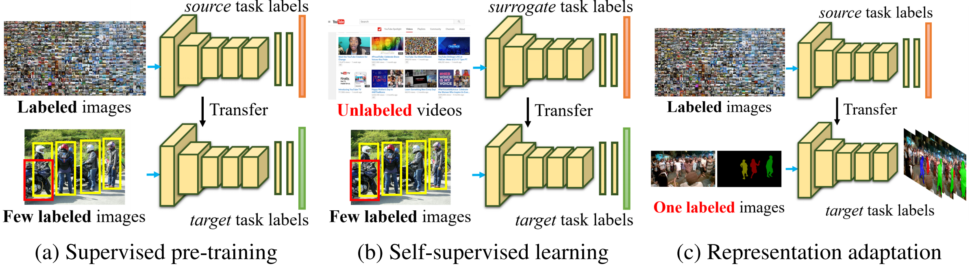
Representation Learning and Adaptation using Unlabeled Videos
Recent success in visual recognition relies on training deep neural networks (DNNs) on a large-scale annotated image classification dataset in a fully supervised fashion. The learned representation encoded in the parameters of DNNs have shown remarkable transferability to a wide range of tasks. However, the dependency on supervised learning substantially limits the scalability to new problem domains because manual labeling is often expensive and in some cases requires expertise. In contrast, a massive amount of free unlabeled images and videos are readily available on the Internet.
This project develops algorithms to capitalize on large amounts of unlabeled videos for representation learning and adaptation. The developed methods significantly alleviate the high cost and scarcity of manual annotations for constructing large-scale datasets. The project involves both graduate and undergraduate students in the research. The research materials are also integrated to curriculum development in courses on deep learning for machine perception. Results will be disseminated through scientific publications, open-source software, and dataset releases.
This research tackles two key problems in representation learning. In the first research aim, the project simultaneously leverages spatial and temporal contexts in videos to learn generalizable representation. The research takes advantages of rich supervisory signals for representation learning from appearance variations and temporal coherence in videos. Compared to the supervised counterpart (which requires millions of manually labeled images), learning from unlabeled videos is inexpensive and is not limited in scope. The project also seeks to adapt the learned representation to handle appearance variations in new domains with minimal manual supervision. The effectiveness of representation adaptation is validated in the context of instance-level video object segmentation.
Sponsors

National Science Foundation